摘要:一、MemcacheMemcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数
wget http://memcached.org/latest
tar -zxvf memcached-1.x.x.tar.gz
cd memcached-1.x.x
./configure && make && make test && sudo make install
PS:依赖libevent
yum install libevent-devel
apt-get install libevent-dev近期,预期作为2024年重要技术方向的redis存储系统引发关注。该系统兼具memcached功能,且在原有基础上新增对各类数值类型(如字符串、链表、散列等)的存储支持;尤其是添加了有序集合和哈希类型的这一革新举措,极大拓展了数据存储及处理多元化选择。
memcached -d -m 10 -u root -l 10.211.55.4 -p 12000 -c 256 -P /tmp/memcached.pid
参数说明:
-d 是启动一个守护进程
-m 是分配给Memcache使用的内存数量,单位是MB
-u 是运行Memcache的用户
-l 是监听的服务器IP地址
-p 是设置Memcache监听的端口,最好是1024以上的端口
-c 选项是最大运行的并发连接数,默认是1024,按照你服务器的负载量来设定
-P 是设置保存Memcache的pid文件存储命令: set/add/replace/append/prepend/cas
获取命令: get/gets
其他命令: delete/stats..python操作Memcached使用Python-memcached模块
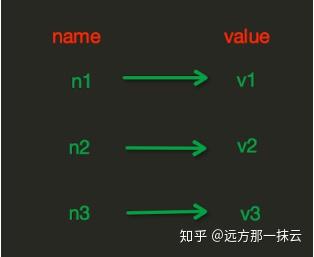
下载安装:https://pypi.python.org/pypi/python-memcachedimport memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.set("foo", "bar")
ret = mc.get('foo')
print ret 主机 权重
1.1.1.1 1
1.1.1.2 2
1.1.1.3 1
那么在内存中主机列表为:
host_list = ["1.1.1.1", "1.1.1.2", "1.1.1.2", "1.1.1.3", ]Redis革命性地增强了其功能,引入内存模式,并实现在线高效的名值数据对技术。不仅沿用旧有字符串、链表及集合等基本数据结构,更扩展了有序集合及哈希两种特色数据类型,使得数据管理与处理更加灵活。
mc = memcache.Client([('1.1.1.1:12000', 1), ('1.1.1.2:12000', 2), ('1.1.1.3:12000', 1)], debug=True)
mc.set('k1', 'v1')#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.add('k1', 'v1')
# mc.add('k1', 'v2') # 报错,对已经存在的key重复添加,失败!!!#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
# 如果memcache中存在kkkk,则替换成功,否则一场
mc.replace('kkkk','999')针对字符串操作,Redis提供了高效便捷的“getset”技术(即通过'name, value'参数实现原有值的修改与新值的设置),为用户提供了强大的字符串管理功用。而在哈希结构方面,Redis以其丰富多样的实用工具,例如'hgetall'(name)、'hlen'(name) 及 'hkeys'(name)等,确保能够高效获取哈希内全部键值、单项键值或剔除特定键值memcache redis,从而提高数据处理效率。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.set('key0', 'wupeiqi')
mc.set_multi({'key1': 'val1', 'key2': 'val2'})#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.delete('key0')
mc.delete_multi(['key1', 'key2'])#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
val = mc.get('key0')
item_dict = mc.get_multi(["key1", "key2", "key3"])关于链表处理,采用`lindex(name, index)`函数,用户便可迅速提取name所属的特定元素。针对集合操作,借助于`sdiff(keys, *args)`及其衍生功能,我们能够精准查找首次满足要求的name所隶属于的集合,且这个集合与其他name集互不相干。而`sdiffstore(dest, keys, *args)`则会将上述特异元素尽数添加到目的地集‘dest’之中。另外,集合操作中的`sintersore(dest, keys, *args)`最适于搜集多数name所隶属集合的交汇部分,其后将结果保存至‘dest’指定的集合并而‘srem(name, values)’,它可以帮您从name所在的集合中移除特定数值;至为关键的是,凭借`sunionstore(dest,keys, *args)`,您可以获取到多个name所对应集合的并集,并将其保存在‘dest’指定的集合内。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
# k1 = "v1"
mc.append('k1', 'after')
# k1 = "v1after"
mc.prepend('k1', 'before')
# k1 = "beforev1after"#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.set('k1', '777')
mc.incr('k1')
# k1 = 778
mc.incr('k1', 10)
# k1 = 788
mc.decr('k1')
# k1 = 787
mc.decr('k1', 10)
# k1 = 777在Redis中,可以运用zincrBY(name, value, amount)函数对有序集的数值实施累积性更新,同时也可用zSCORE(name, value)获取关键值与相应得分。对于数据的清理,用户可使用delete(*names)高效执行。若是要将其中某键值移入特定数据库,那么可运用move(name, db)命令实现。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True, cache_cas=True)
v = mc.gets('product_count')
# ...
# 如果有人在gets之后和cas之前修改了product_count,那么,下面的设置将会执行失败,剖出异常,从而避免非正常数据的产生
mc.cas('product_count', "899")1. 使用Redis有哪些好处?
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
2. redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
3. redis常见性能问题和解决方案:
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3...
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
4. MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
5. Memcache与Redis的区别都有哪些?
1)、存储方式
Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。
Redis有部份存在硬盘上,这样能保证数据的持久性。
2)、数据支持类型
Memcache对数据类型支持相对简单。
Redis有复杂的数据类型。
3),value大小
redis最大可以达到1GB,而memcache只有1MB
6. Redis 常见的性能问题都有哪些?如何解决?
1).Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
2).Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
3).Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
4). Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
7, redis 最适合的场景
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
、Redis支持数据的备份,即master-slave模式的数据备份。
、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
(1)、会话缓存(Session Cache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
(2)、全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。
此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)、队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看。
(4),排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的,你可以在这里看到。
(5)、发布/订阅
最后(但肯定不是最不重要的)是Redis的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)。
Redis提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。Redis研发团队对新特性发表评论称:“我们翘首以盼新功能的上线。借助于valuestorage类型的扩充,我们坚信Redis将能更好地应对更广泛的数据需求,从而提高用户的使用感受和价值。”
wget http://download.redis.io/releases/redis-5.0.2.tar.gz
tar xzf redis-5.0.2.tar.gz
cd redis-5.0.2
make
cd src
make install PREFIX=/opt/redis
make testsrc/redis-cli
redis> set foo bar
OK
redis> get foo
"bar" 根据最新的统计数据显示,自从Redis推出新功能后,已经有大量用户选择使用该升级版产品,其作用范围广泛memcache redis,涵盖了各个行业的数据储存和处理环节。
sudo pip install redis
or
sudo easy_install redis
or
源码安装
详见:https://github.com/WoLpH/redis-py#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print r.get('foo')据专家称,实施 Redis 新增特性有望提高开发人员的使用便利性和适应力。这将满足数据多样性需求,并助力提升数据高效处理效能,对于大规模数据解析及实时应用环境建设具有战略意义。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')该公告发布后立即在业内产生了热烈反响和深入研究。众多行业成员积极回应,热情洋溢地赞赏Redis新功能,期盼借此提升数据管理能力与实际应用成果。
该突破对云计算、物联网乃至人工智能等诸多领域具有深远影响。随着数据容量的迅速扩张,对高效、稳定且灵活的数据存储与处理技术的需求日益迫切。Redis作为一款注重性能的数据库管理系统,其最新版本通过引入多类型Value存储,有效满足了这一需求。2024年度推出的这项重要更新实现了更多可能性,使得各行各业在处理和存储数据方面更具灵活性和便利性。我们有理由相信,当这一变革投入全面使用时,数据存储与处理领域将呈现出更具创新性且高效的发展趋势。
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)欢迎广大读者在评论区积极发表对Redis新功能的看法与思考。若本文切实符合您的需求,请慷慨地向相关领域的同仁分享,以引起他们对这项重大突破的关注。让我们携手共进,见证科技创新推动美好未来!
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})批量获取
如:
mget('ylr', 'foo')
或
r.mget(['ylr', 'foo'])